DEVELOPMENT OF AN ANALYTICAL SYSTEM FOR ASSESSING THE EMERGENCE OF PUBLIC HEALTH RISKS ON THE BASIS OF MACHINE LEARNING ALGORITHMS
DEVELOPMENT OF AN ANALYTICAL SYSTEM FOR ASSESSING THE EMERGENCE OF PUBLIC HEALTH RISKS ON THE BASIS OF MACHINE LEARNING ALGORITHMS

Abstract
The work examines the specifics of creating and describing the possibilities of using an analytical system for assessing the emergence of risks to public health on the basis of machine learning algorithms. Literature sources and authors' studies on the evaluation of anthropogenic environmental factors and the problems of their negative impact on human health have been analysed. The formalization of the used data set for the analysis of the level of polluted air has been performed, its structure has been described, input attributes have been indicated, the results of exploratory and correlation analyses have been given, machine and deep learning models have been built, their operation has been studied and the values of metrics characterising the accuracy of their operation have been estimated. The results are analysed, the most effective models are identified and ways of further improvement are outlined.
1. Введение
Проблема автоматизации процессов анализа разнородных и больших объемов экологических данных приобретает все большую актуальность и востребованность, что во многом связано с необходимостью внедрения эффективных мер превентивного препятствия развитию человеческих заболеваний, вызванных различными антропогенными факторами , . В контексте существующих риск-ориентированных подходов по оценке последствий возникновения техногенных факторов и их влияния на здоровье населения дополнительную целесообразность приобретают современные подходы к анализу данных, основанные на применении технологий искусственного интеллекта (ИИ), алгоритмов или моделей машинного (МО) и глубокого (ГО) обучения, в том числе искусственных нейронных сетей (ИНС) . Подобные концепции имеют преимущества над существующими статистическими и математическими подходами благодаря поддержке процедур формирования обобщающей способности моделей, унификации предиктивных алгоритмов и возможностям интерпретации результатов в наглядном виде , .
2. Анализ литературных источников и проблематики
В настоящее время проблеме анализа данных в области оценки рисков здоровья населению в контексте экологического загрязнения посвящено значительное число научных трудов, рассмотрим популярные практики и подходы, нацеленные на автоматизацию процессов решения интеллектуальных задач.
В статье авторами рассматриваются ИИ и методы МО для предсказания загрязнения воздуха и последствий для здоровья, включая хронические респираторные заболевания. Исследователи подчеркивают высокую точность гибридных моделей, комбинирующих различные алгоритмы для прогнозирования загрязняющих веществ. Они оценивают модели по метрикам точности, таким как RMSE и MAE, отмечая их эффективность в раннем оповещении о рисках для здоровья, однако дисбаланс входных выборок данных вносит существенные коррективы в полноту.
Исследование основано на применении модели случайного леса для анализа влияния антропогенных выбросов и метеорологических факторов на долгосрочные изменения уровня загрязнения воздуха в восточном Китае. Результаты проведенного анализа данных показали, что значительное снижение загрязнения связано с уменьшением различных антропогенных выбросов в атмосферу ряда локаций. Модель МО позволила выявить тренды сезонных колебаний в загрязнениях воздуха, что позволило провести более точную оценку рисков здоровья населения при различном уровне концентрации вредных веществ, при этом точность модели оказалась достаточно высокой, более 86%.
Авторы оценивают несколько разных моделей ГО, включая LSTM и Bi-LSTM, для прогнозирования уровней загрязненности воздуха примесями PM2.5 и CO. Исследователи установили, что модель Stacked LSTM показала более высокий уровень точности для PM2.5, а Encoder-Decoder LSTM – для значений CO. Результаты использования моделей могут быть использованы для информирования о краткосрочных (горизонт прогнозирования составил от 1 до 3 дней) значениях рисков для здоровья. Также в рамках данной работы рассмотрено применение алгоритмов классификации (SVM) для выявления уровня корреляции между степенью загрязненности воздуха и заболеваниями, связанными с дыхательной и сердечно-сосудистой системами.
В другом исследовании на базе применения МО авторы создали две MS2Quant модели для прогнозирования эффективности ионизации и модель MS2Tox для оценки токсичности продуктов аквакультур. Созданные авторами модели применимы для определения потенциально опасных химических веществ в воде на основе анализа данных по спектрам масс и позволяют повысить уровень быстродействия идентификации и классификации загрязнителей в сточных водах, которые потенциально оказывают влияние на оценку риска здоровью.
В работе авторами исследованы методы ансамблевого обучения для оценки качества грунтовых вод в районе бассейна Гуанчжун. В частности, применены модели LightGBM в комбинации с анализом неопределенности и SHAP подходом для прогноза параметров качества загрязненной воды. Модели позволяют учесть влияние антропогенных и природных факторов, что помогает выявить ключевые риски для здоровья, однако их точность сильно зависит от значений входных гиперпараметров.
Таким образом следует отметить, что в настоящее время в научной среде много внимания уделяется специфике применения методов МО и ГО для задач автоматизации анализа экологически значимых для здоровья населения данных, в связи с чем данная тематика является актуальным и востребованным направлением.
Цель работы заключается в разработке аналитической системы оценки возникновения рисков здоровью населения на базе алгоритмов машинного обучения.
3. Разработка концепции системы
Рассматриваемая нами задача сводиться к многоклассовой классификации. Задача многоклассовой классификации в машинном обучении – это задача предсказания, где модель должна определить, к какому из нескольких возможных классов принадлежит наблюдаемый объект. Математическая постановка этой задачи в рамках оценки рисков нанесения вреда здоровью населения может быть выражена следующим образом. Наш входной набор данных может быть представлен как X={x1, x2, ...,xn}, где каждый объект xi является вектором признаков из пространства ℜd. Каждому объекту xi сопоставляется метка класса yi∈{1,2,...,K}, где K – количество классов (6 классов в рамках нашей задачи).
Требуется построить функцию f:Rd→{1,2,...,K}, которая для любого входного объекта x будет предсказывать метку класса y (риск здоровью населения). Модель МО строится с использованием обучающей выборки {(x1,y1),(x2,y2),...,(xn,yn)}, которая может быть сформирована из информативных входных признаков и ее задача — найти аппроксимацию функции f на основе этих данных. Если P(y=k|x) – вероятность принадлежности объекта x классу k, то функция f(x) предсказывает класс с максимальной апостериорной вероятностью:
Для обучения модели используется функция потерь, которая измеряет расхождение между предсказанными классами и реальными метками классов.
Одной из часто используемых функций потерь является кросс-энтропия:
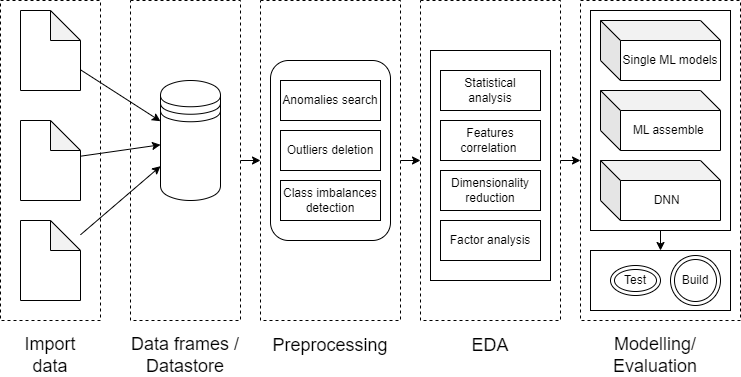
Рисунок 1 - Общий пайплайн работы системы
Дисбаланс классов реализован на базе подхода, основанного взвешивания классов, т.е. путем расчета значений весов в виде обратной величины частоты класса в выборке (фактически возрастает уровень штрафа модели для менее распространенных классов в датасете). Генерация синтетических данных не предусмотрена, что положительно сказывается на достоверности классификации. Сформированные модели оцениваются по выбранным метрикам оценки качества (точности) их работы, тестируются и их итоговые объекты сериализуются в отдельные файлы для последующей загрузки для использования на новых данных с целью оценки рисков вреда населению.
4. Описание датасета
В процессе осуществления процедуры поиска доступных наборов данных для проведения исследований влияния различных антропогенных факторов на здоровье населения выявлено, что в свободном доступе отсутствуют комплексные датасеты, отражающие разные аспекты экологической загрязненности. В большей степени на платформах анализа данных и в открытых репозиториях превалируют наборы данных по загрязнению воздушных масс различных регионов мира, в том числе в странах Индии. В качестве базового набора данных возьмем Air Pollution Dataset from India and Nepal (APD) . Представляет собой составной набор данных, который содержит изображения, собранные в Индии и Непале, описывающие и характеризующие уровень рисков вреда людям от уровня загрязнения воздуха различными вредными веществами в различных условиях, а также текстовые наборы данных с детализацией описания данных по значимым признакам. Региональная специфика датасета заключается в учете визуальных изображений разных регионов, что дополняет общую информацию, представленную в табличном виде в формате csv, конкретизируя особенности распределения загрязнений в разных локациях Индии и Непала.
Особенность набора данных заключается в том, что изображения сделаны с разными уровнями загрязненности и могут быть использованы для анализа с применением методов компьютерного зрения и МО. Размер выборки составляет около 12 000 записей, распределение целевых классов приведено в примерно равных пропорциях (от 13 до 21%). Также данные агрегированы на базе сбора информации из 2 разных государств с отличными друг от друга экологическими и социально-экономическими условиями (Индия и Непал), что позволяет проводить сравнительный анализ данных по локациям.
Следует отметить, что в этом наборе данных предусмотрен потенциал анализа не только данных, полученных с измерительных средств состава воздуха, но и анализ визуальных признаков загрязнения (что позволяет сформировать большее признаковое пространство и учесть сложноформализуемые факторы), что может быть полезно для более комплексной оценки. Т.е. данные могут использоваться совместно с метеорологической информацией и измерениями здоровья населения для комплексной оценки рисков. Структурно датасет разделен на два каталога: Combined_Dataset и Country_wise_Dataset. Датасет включает информацию о городе Биратнагар Непала и о городах Индии: Дели, Нагаленд, Бангалор, Большая Нойда, Фаридабад, Мумбаи, Тамил Наду. Входные признаки датасета хранятся в файле формата csv и содержат информацию о расположении локации, имени файла (изображении), дате (год, месяц, день, час), а также показателях загрязненности воздуха (PM2.5, PM10, O3, CO, SO2, NO2) и целевом классе AQI_Class. В качестве целевого признака предусмотрено 6 разных классов загрязнения воздуха, которые представлены в наборе данных:
1. Хорошее (Good), соответствует числовому диапазону (0-50), в этом случае качество воздуха считается удовлетворительным, а загрязнение воздуха представляет небольшой или нулевой риск населению.
2. Умеренное (Moderate), соответствует числовому диапазону (51-100), для данного класса качество воздуха приемлемое, однако для некоторых загрязняющих веществ может быть умеренная проблема со здоровьем для очень небольшого числа людей, которые необычно чувствительны к загрязнению воздуха, т.е. риски населению в целом минимальны.
3. Нездорово для чувствительных групп (Unhealthy_for_Sensitive_Groups), соответствует числовому диапазону (101-150), в этом случае люди, относящиеся к чувствительным группам, могут испытывать последствия для здоровья, но маловероятно, что население в целом будет испытывать высокий риск развития хронических заболеваний, можно интерпретировать класс как низкий уровень риска.
4. Нездоровый (Unhealthy), соответствует числовым значениям в диапазоне (151-200), для данного класса выходного признака более половины представителей общественности может испытывать проблемы со здоровьем, обострением заболеваний, а у представителей уязвимых групп могут возникнуть серьезные проблемы со здоровьем. Средний уровень риска.
5. Очень нездоровый (Very_Unhealthy), соответствует числовому диапазону (201-300), в данном случае риск необратимых пагубных последствий для здоровья населения высок для всех групп.
6. Опасный/тяжелый (Severe), соответствует числовым значениям в диапазоне (301-500), характерно для критических и чрезвычайных ситуаций, в том числе аварий, высокая вероятность необратимого вреда здоровью населения, уровень риска критический.
5. Разведывательный анализ данных
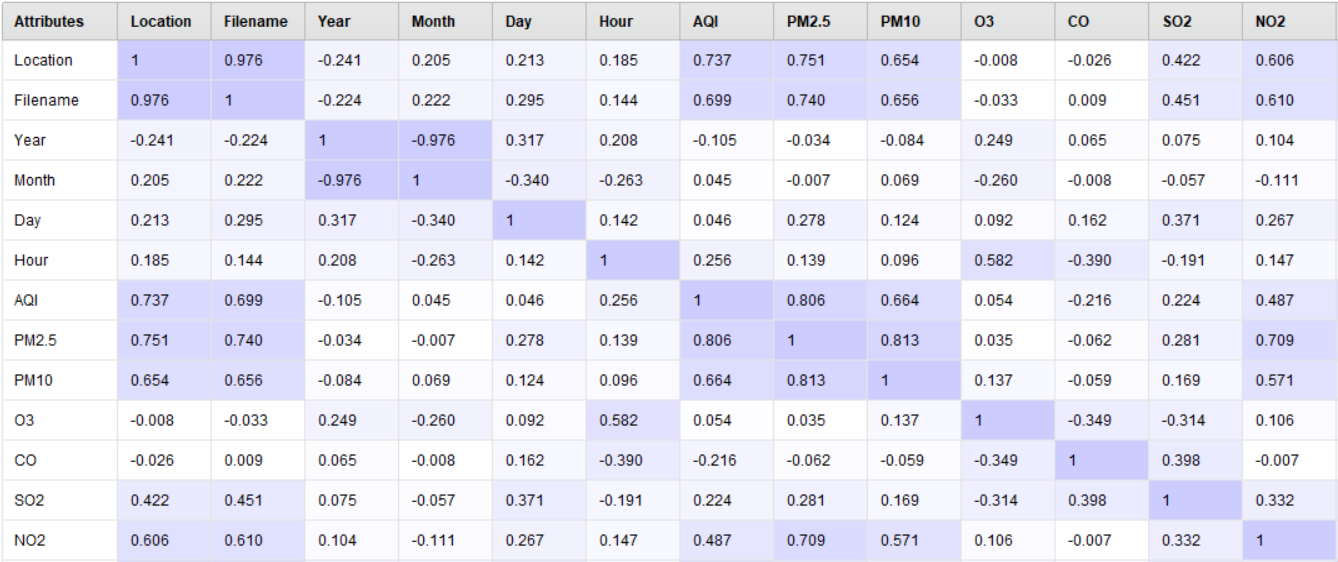
Рисунок 2 - Таблица оценки корреляции между входными признаками набора данных
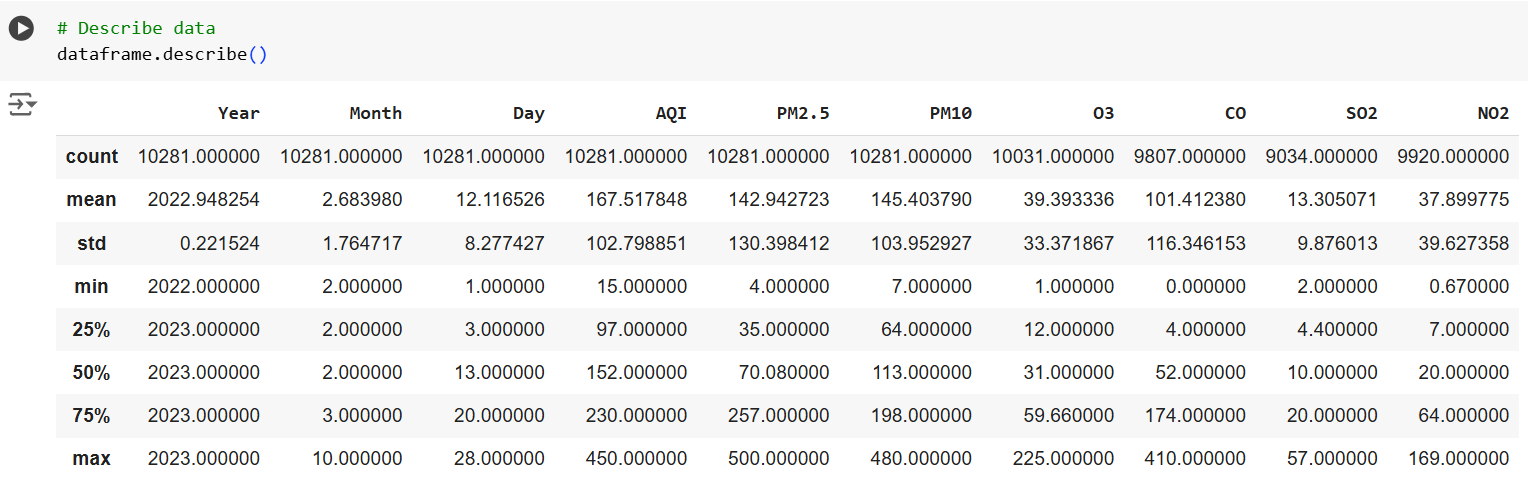
Рисунок 3 - Результат оценки статистических показателей
На базе проведенных манипуляций установлено, что признаки месяц и год обладают высокой корреляцией и некоторой противоречивостью, в связи с чем они исключены из итогового набора данных. В процессе реализации процедуры анализа пропусков посредством вызова метода isnull() установлено наличие более 2000 пропусков в признаках O3, CO, SO2, NO2, в связи с чем было выполнено заполнение пропущенных значений путем расчета и подстановки средних значений посредством вызова функции mean().
6. Разработка и исследование моделей
Для разработки моделей МО использован язык программирования Python, библиотеки sklearn, matplotlib, seaborn, keras, tensorflow , , на базе чего сформированы отдельные модули Jupiter Notebooks, в каждом из которых реализованы процессы импорта программных зависимостей (библиотек), входных данных (тренировочной и тестовой выборок), созданы (обучены и протестированы) советующие модели, проведена оценка их эффективности на базе описанных выше метрик, а также выполнена сериализация моделей в файлы объектов pickle. В качестве моделей МО реализованы: дерево решений (DT), SVM, случайный лес (RF), XGBoost, глубокие ИНС (сверточная – CNN и рекурентная – LSTM).

Рисунок 4 - Матрицы ошибок моделей дерева принятия решений (а), SVM (б), случайного леса (в), XGBoost (г), рекуррентной (д) и сверточной (е) ИНС
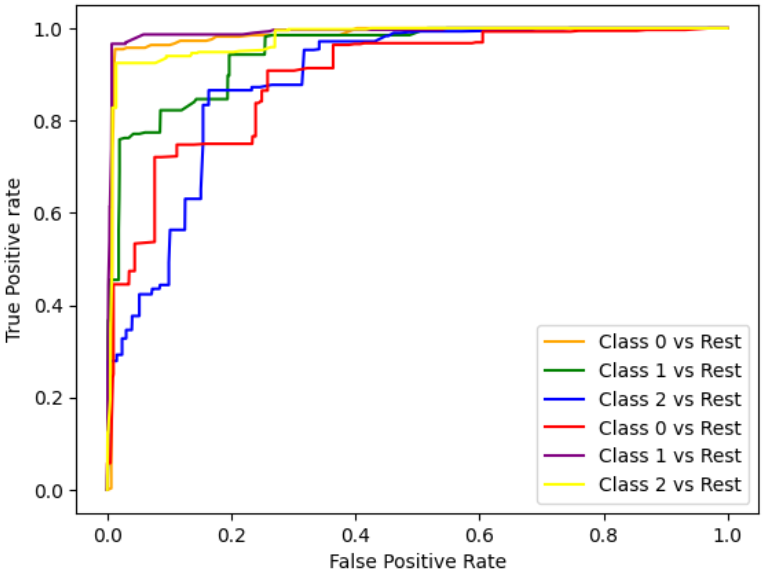
Рисунок 5 - Усредненные зависимости по ROC кривым моделей
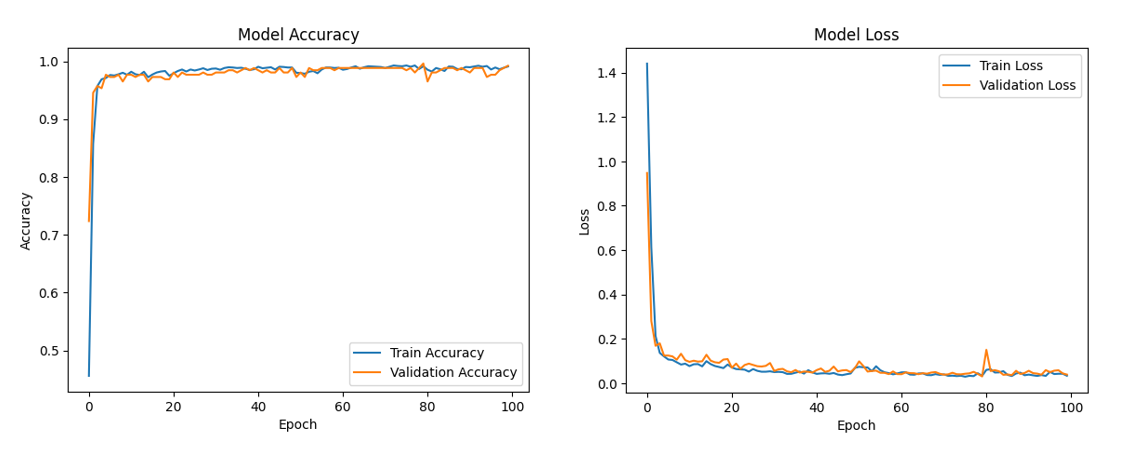
Рисунок 6 - Зависимости значений Accuracy и Loss от эпох обучения рекуррентной ИНС
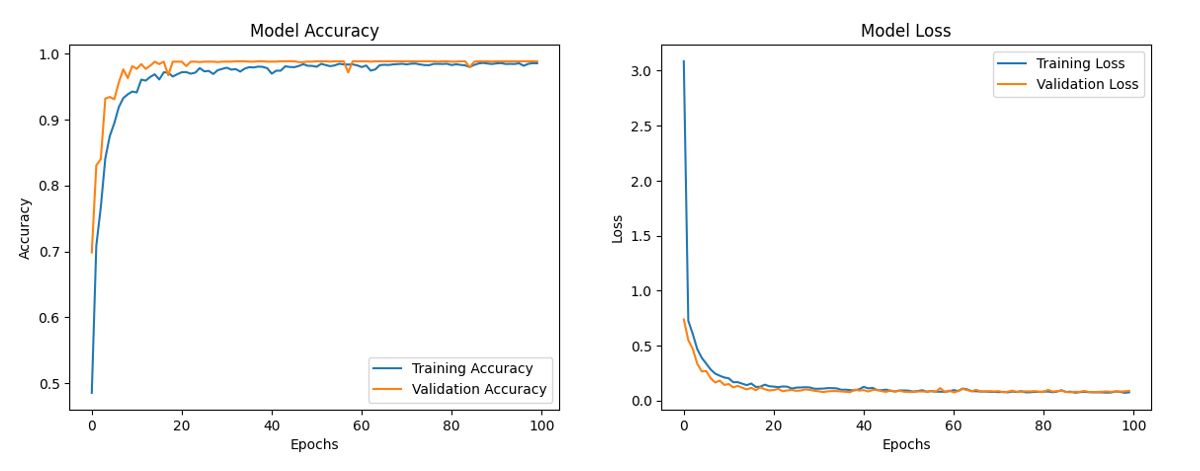
Рисунок 7 - Зависимости значений Accuracy и Loss от эпох обучения сверточной ИНС
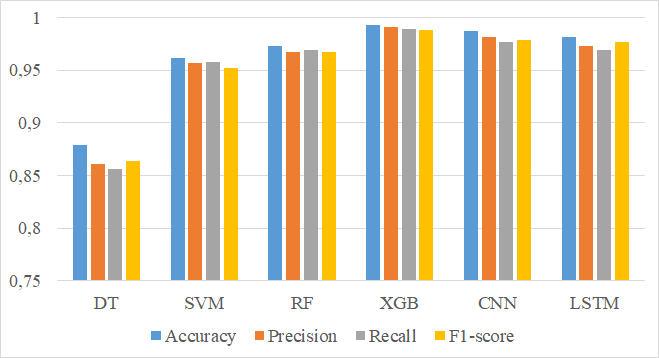
Рисунок 8 - Гистограмма сравнения метрик моделей МО
Как можно заметить наибольший уровень значимости характерен для признаков AQI, PM2.5 и PM10, что позволяет сделать вывод о необходимости формирования на них акцента при построении моделей и дальнейшей их оптимизации.
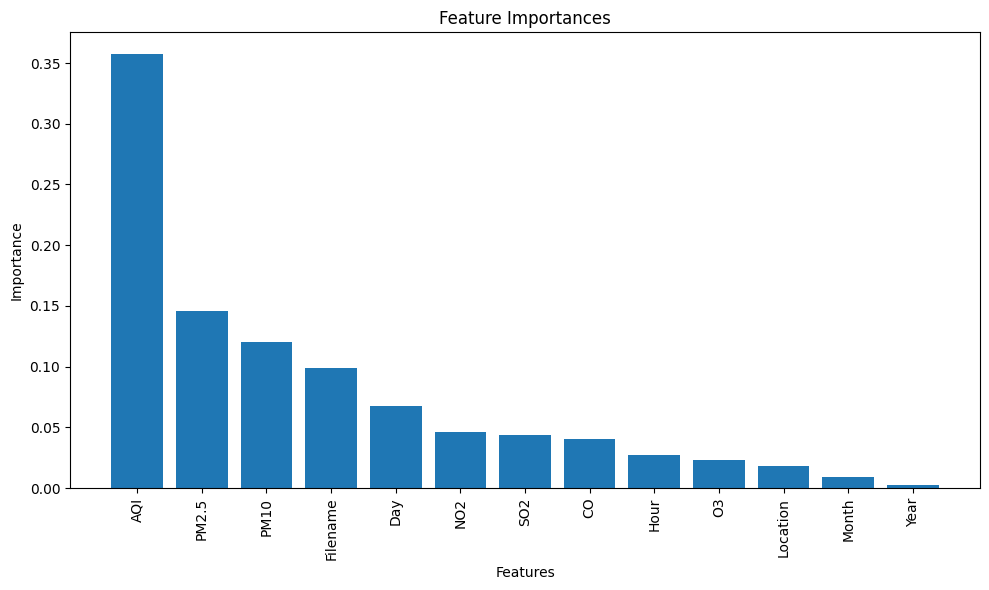
Рисунок 9 - Гистограмма оценки значимости признаков датасета
7. Заключение
В результате проведенных исследований установлена практическая целесообразность применения разных моделей МО и ГО для решения задачи классификации по оценке рисков вреда здоровью населения от загрязнений воздуха. В целом точность сформированных моделей является достаточно высокой и составляет более 90%, однако скорость их обучения и использования на тестовых данных является разной, с точки зрения наилучшего соотношения по точности и производительности следует отметить модели ансамблей (Random Forest и XGBoost).
В настоящий момент система ограничена рядом аспектов, в частности на данный момент процессы обучения и настройки моделей выполняются только в последовательном режиме, отсутствует поддержка распределённой архитектуры CUDA и входные данные могут вводиться посредством текстового файла (без интерактивного интерфейса пользователя). Следует отметить необходимость подбора моделей и значений их гиперпараметров под конкретные наборы данных, одни из перспективных путей в данном направлении является применение алгоритмов оптимизации, в том числе grid search подхода, что может быть рассмотрено в последующих исследованиях в данной области.